Last modified: Thu Oct 25 2001
SPOC-architecture
by Tobias Öbrink
Table of Contents
This is a document describing a proposed architecture for a service developed from the Single-Point-Of-Contact (SPOC) concept. In short the concept suggest that a single, well-known point should be used to simplify the different stages of a communication setup between persons or person-service or service-service. I will use a simple graph to help explain the concept.
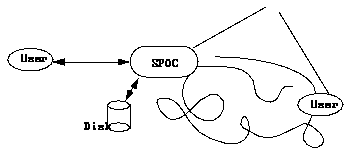
Figure 1. A very simple SPOC
Here we have two users, one active and one passive. The active user is looking for aperson to ask about some strange acronym, SPOC, that he have encountered. In this valiant quest for knowledge he happen to connect to a SPOC consisting of a simple Web-server with a list of all employed at the dept. of Teleinformatics, KTH, Sweden. Except from name, the list entries also consists of
- a link to the employees home page, if present. A link to a cgi-script running "finger" on the employee, otherwise
- a link to a more or less recent photograph of the employee
- the employees position
- the employees telephone number(s)
- which room the employee is most frequently located in
- the employees email address
With the help of this list and additional information on the employees home pages, the active user hopefully will find a person to ask, and he will also know how to contact the passive user.
This of course is a very simple SPOC that also requires that the active user have access to a Web browser. A more ideally SPOC should offer a lot more information, search engines and not to forget gateways.
The keyword in an ideally SPOC should be "Accessability". It should be possible to connect to it even by a smoke signals protocol. To achieve this (accessability, not smoke signals) the SPOC should have
- a well-defined physical location
- a well-defined network location
- a multitude of gateways to different communication protocols
- an information repository describing the SPOC architecture
- some reason for being
Point 1 - 3 is (I hope) quite self-explanatory. Point 4 is for making administration of the SPOC easier. Point 5 is very important.
Now, over to the proposed architecture. I would like to start with the overall functionality, which is divided into as independent modules as possible.
So far I've been able to identify the following groups of functionality
- the External user Object
- the Internal user Object
- the Information Repository
- the Gateway Object
- the Manager
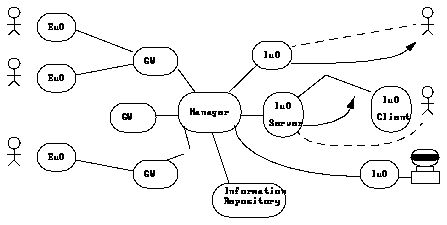
Figure 2. Functionality modules in the proposed SPOC system
The External user Object is the part of the system that the Active user will use in his/hers interactions with the SPOC. Naturally the behaviour and the "look and feel" of the External user Object will vary with which media is used; an external user connected via an ordinary telephone will need a different UI than an external user connected via a direct 2.5 Gbps link with separate video, audio and data channels. Some other users may want to send a fax, or an email or connect via some text-terminal-based protocol, and some users may want to recieve responses via a different medium than was used for the request. It should be launched by the Manager as a result of a request from the contacted Gateway Object. The External user Object uses the contacted Gateway Object in its interactions with it's Active user.
The Internal user Object is the part of the system that will keep track of it's "Internal user". This "Internal user" could be a person or some network service (Directory Server, Web server, search engine, file server, you name it). It's only "internal" in the sense that it's within the scope of knowledge that the SPOC possess. The Internal user Object keeps updated the information regarding it's Internal user in the Information Repository.
The Information Repository handles all information contained in the SPOC system. This includes information describing the architecture and configuration of the SPOC as well as information about Internal users, status information and messages. The Information Repository should be the most robust part of the system, because the information contained there can be used to rebuild the system automatically and because the information contained therein is the reason why people bother to use it at all.
The Gateway Object handles translation between the internal SPOC protocol/medium and some other protocol/medium as well as launching and managing External user Objects specific for the appropriate protocol/medium. It should be closely connected to the Manager.
The Manager is the spider in the net. It should have the two first characteristics of a SPOC above. It should be closely connected to the Information Repository to be able to keep track of connections and parts in the system. It should handle requests for information from all other parts of the SPOC system and all initiation of cross-protocol/media communication. It should alsom be able to relay requests to other Managers in other SPOCs that are registered as Internal user Objects in this SPOC.
There are ofcourse a lot of ways you can map the above described functionality onto SW/HW-entities and it requires some consideration and discussion to do it efficiently and well. Here are the currently proposed solutions.
So far only an WWW-based External user Object have been considered. It should be implemented as a Java applet that can be downloaded from a WWW-gateway. It will then communicate with the Manager (and other objects in the system) through this gateway via a cgi-script or some other serverdaemon running on the same machine.
The Internal user Object should be a pair of intelligent agents. One on the system side and one on the user side, if possible. A third agent in the Information Repository could be used to help in accessing the user information. Three designs of the agent on the system side are currently debated:
- The very decentralised scheme, where the system part implementing the Internal user Object also includes all data about it's user. In this scheme, the Internal user Object is also a part of the Information Repository.
- The partly decentralised scheme, where the system part implementing the Internal user Object also includes all "dynamic" data about it's user. In this scheme, the Internal user Object is also a part of the Information Repository.
- The centralised scheme, where the system part implementing the Internal user Object provides only intelligence and is completely separate from the Information Repository.
All these schemes have their advantages:
- The very decentralised scheme. The Internal user Object have complete control over all data concerning it's user, the accesstime for updating the data is very low.
- The partly decentralised scheme. Most Directory Services tend to be optimized for "static" data and the "dynamic" data is of little interest if the part of the system running the Internal user Object is down. The accesstime for updating the dynamic data is very low.
- The centralised scheme. From a stability and security point of view it's preferable to have all the information in one place. Also the system part implementing the Internal user Object can be very lightweight.
All these schemes also have setbacks ofcourse:
- The very decentralised scheme. Can get tricky to uphold data consistency and security. The database management work, storage- and backup demand and security mechanisms introduces extra complexity in the system part and will be quite heavyweight.
- The partly decentralised scheme. Unfortunately the same as 1 above, even though the storage - and backup demand is lower.
- The centralised scheme. The communication with the Information Repository will demand some efforts to avoid becoming a bottleneck.
There's a lot of issues to consider when choosing which way to go here, and maybe we'll find additional options further on.
The other two agents have been only briefly mentioned.
The design of the Information Repository is dependent on which scheme will be choosed for the system part of the Internal user Object above. Additionally, it will include a Directory Service containing a description of the system. Apart from the issues discussed above, there is an issue on the general architecture of the Information Repository:
- The decentralised scheme. The Information Repository consist of an arbitrary number of interlinked Directory Services with a well-known "entrance" consisting of links to all other directories, or links to the top directories of a tree structure.
- The centralised scheme. The Alta Vista approach.
And the questions involved as far as I have got in my reading:
- The decentralised scheme. Mostly internal indexing issues. How to support searches, listings and administration? How to handle interaction between different parts of the Information Repository that consists of different solutions, speaking different protocols and having different data structures?
- The centralised scheme. Scalability issues. How to avoid becoming a bottleneck?
The Directory services I've stumbled onto so far is
- X.500 with DAP or LDAP client
- LDAP server with LDAP client
- CCSO Name server with it's own client
- WebNFS/NFS with WebNFS/NFS-client or FTP
More study is needed.
An impressive amount of different gateway products between different protocols and media have been released recently. Often connected to the WWW to get publicity. My vision is to use all these gateway products to get access to the SPOC-system by as many channels as possible and allow persons and services to communicate without having to bother about media/protocol/whatever restrictions.
A Gateway Object should consist of a gateway product managed by an agent.
Currently identified Gateway Objects are:
- Internet telephones
- Ordinary telephones
- Email
- Fax
- WWW/Java
- Telnet
- FTP
- Video/Audio server/client applications
- Videoconferencing applications
- Graphical VR-applications
- Text-based chat and VR-applications
An ideal Manager would be a combined "marketplace-court-townhall" for a software agent population continuously haggling about resources and information. It should supervise the activity, solve conflicts, mediate communication and optionally run a FAQ-cache for the agents. It should be closely connected to the part of the Information Repository containing a description of the system. It could be partly distributed on other parts of the system to avoid becoming a bottleneck.
3 Additional use-cases
In addition to the example given in the Introduction above I've cooked up a few use-cases to show some possible functions.
- Search for a person based on his/her profile - name, competence/expertice, locality, ...
- Temporary redirections can be programmed with a start- and end time just like it is done in common telephone switch boards, email servers and SIP servers separately today. The difference would be that the user doesn't have to remember to change his redirections in each of these directories. Moreover, the user's agent would have ask the correct questions to be able to perform the task, much like one of those popular configuration wizards commonly used today, thus liberating the user from knowing which data should be in which directory.
- An internal user may decide which information to show to whom/what. E.g. home telephone number may be visible only to your boss and to support personel during certain time intervals.
- The Internal User Agent can push information to some recipients about your status. E.g. "John Doe work from home today due to illness. Can only be reached by email and snail-mail".
- Translation between different media in an organized and consistent fashion can be the result of a capability negotiation between the External User Object and the Internal User Object. The External User Object may notify it's External User, connected via telephone, that "The person you seek is currently only available via
- email. Do you want to leave a voice-to-text message?
- SIPphone. Do you want me to forward the call?
- Internal User Objects representing non-personell resources can be used to
- check status and book meeting rooms,
- check status of fax machines, copier machines, printers, vending machines, refrigerators and other machinery,
- obtain data on location of resources, numbers to receptionists and other support functions.
More work, reading and thought are needed.
Maintained by
Tobias Öbrink